

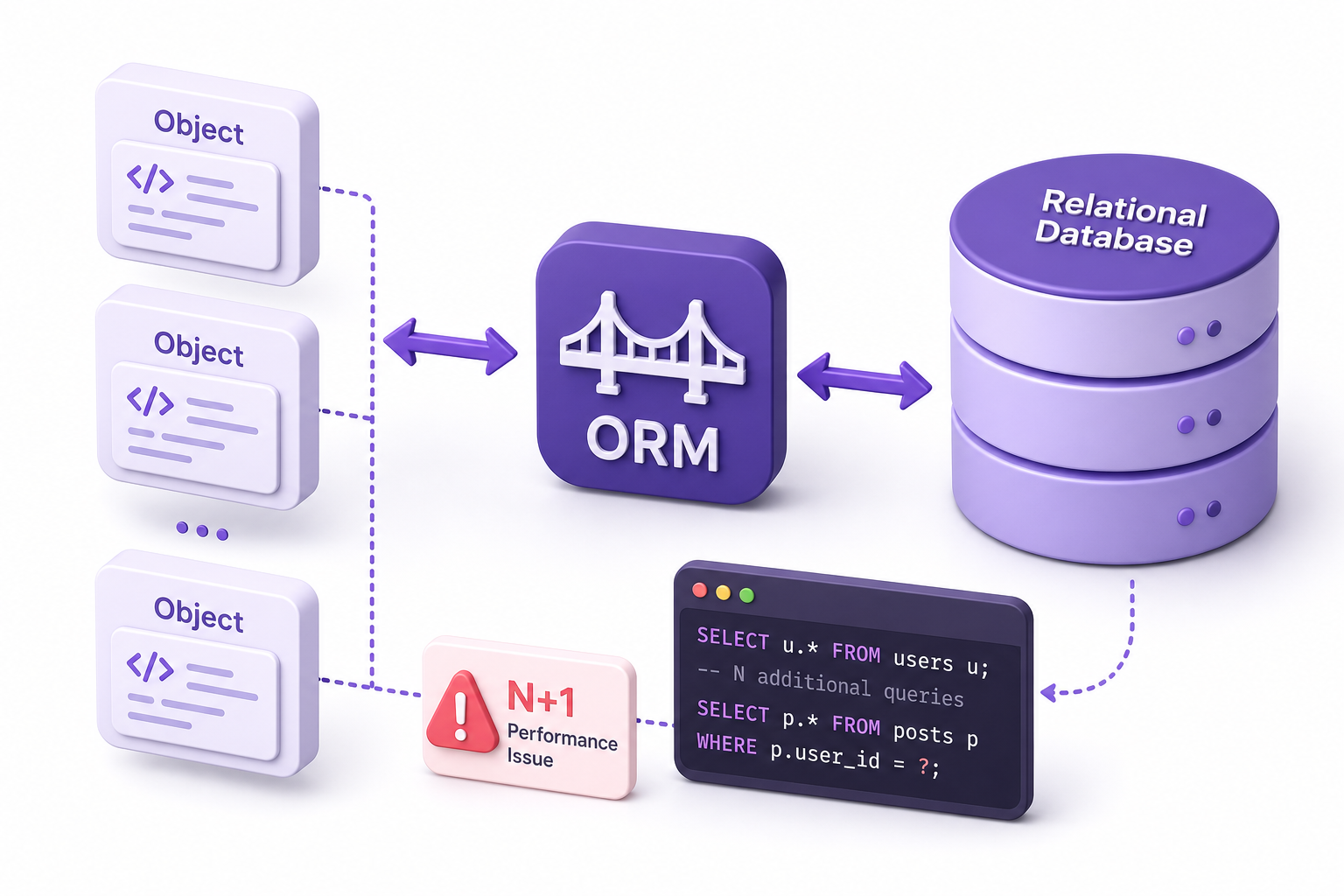
An Object-Relational Mapper sits between your domain objects and your relational tables and translates one into the other. You write user.orders and the ORM writes the SQL, parses the rows, and hands you back typed objects. Hibernate and JPA do this in Java, Entity Framework in .NET, ActiveRecord in Rails, and Sequelize, TypeORM, and Prisma in the Node world. They remove a huge amount of boilerplate, and they remove it well enough that most developers never look at the SQL underneath. That is exactly where the trouble starts. ORMs do not make the database go away. They hide it, and most production performance disasters trace straight back to that hidden layer.
The Impedance Mismatch
Objects and tables do not model the world the same way, and the gap between them has a name: the object-relational impedance mismatch. An object graph has references, inheritance, and identity. A relational schema has rows, foreign keys, and joins. The ORM bridges the two, but the bridge leaks.
Type and collation mismatches are the first leak. A database VARCHAR carries an encoding and a collation - the rules for character ordering and whether A and a compare as equal. Your application string has none of that. A query that looks fine in code can return different results, or skip an index, because the column collation does not match what the comparison expects. Numeric precision, time zones on timestamps, and enums all have the same problem: the object type and the column type agree until they suddenly do not.
Inheritance is the second. There are three common ways to map a class hierarchy to tables - table per hierarchy, table per concrete class, and table per class with joins - and they have very different performance profiles. Table per hierarchy is one wide table with nullable columns and no joins. Table per class is normalized but pays a join on every read. The ORM lets you pick with an annotation, which makes it easy to choose without thinking about the query plan you just signed up for.
A practical defense is to keep a separate entity model from your domain model. Put the mapping annotations on the entities, not on the objects that hold your business logic. It is more code, but it stops persistence concerns from bleeding into the domain and gives you one place to reason about how objects become rows.
N+1 Is the Headline Pitfall
If an ORM is going to wreck your latency, this is usually how. Take aircraft, each with many seats, and a loop that touches the seat collection:
aircrafts = aircrafts.load();
for (aircraft in aircrafts) {
seatsCount = aircraft.seats.size;
}
With lazy loading on the seats relationship, that innocent loop runs one query for the aircraft and then one more query per aircraft to fetch its seats:
SELECT * FROM aircrafts;
SELECT * FROM seats WHERE aircraft_code = 1;
SELECT * FROM seats WHERE aircraft_code = 2;
SELECT * FROM seats WHERE aircraft_code = 3;
-- ...
SELECT * FROM seats WHERE aircraft_code = n;
One query becomes N+1. With 500 aircraft, that is 501 round trips, each with its own network and planning cost. The fix is to fetch the related data up front with a join:
SELECT * FROM aircrafts
LEFT JOIN seats ON seats.aircraft_code = aircrafts.aircraft_code;
In ORM terms that means eager loading: JOIN FETCH in JPA/Hibernate, Include in Entity Framework, includes in ActiveRecord, include in Prisma, or include/relations in Sequelize and TypeORM. The trap is doing it globally. Mark a relationship eager everywhere and you pull data you never use on every read, which brings us to the opposite failure.
When Eager Loading Becomes the Problem
Eager loading is not free, and one big join is not always the fast path. Picture a user with seven unrelated child collections - details, pages, texts, questions, reports, location, peers - all pulled in one query:
const user = repository.get("user")
.where("user.id = 123")
.leftJoin("user.details", "user_details_table")
.leftJoin("user.pages", "pages_table")
.leftJoin("user.texts", "texts_table")
.leftJoin("user.questions", "questions_table")
.leftJoin("user.reports", "reports_table")
.leftJoin("user.location", "location_table")
.leftJoin("user.peers", "peers_table")
.getOne();
That produces one query joining seven tables against the same root. Each join multiplies the rows. If the user has 10 pages, 20 texts, and 30 questions, the database returns the Cartesian product of those collections - the row count explodes into the hundreds of thousands, and the ORM then flattens all of it back down to a single object. A query like this can run for tens of seconds and ship a third of a million rows across the wire just to build one user.
Splitting it apart is faster, even though it issues more queries:
SELECT * FROM users AS user WHERE user.id = '123';
SELECT * FROM users AS user
LEFT JOIN user_details_table AS detail ON detail.user_id = user.id
WHERE user.id = '123';
SELECT * FROM users AS user
LEFT JOIN pages_table AS page ON page.user_id = user.id
WHERE user.id = '123';
-- one query per collection
Each query returns a small, bounded result, and the set can finish in single-digit milliseconds. The general rule: join when the relationship is to-one or the child set is small, split into separate queries when you are fanning out across several independent to-many collections. Lazy versus eager is not a setting you flip once. It is a decision per access pattern.
Transactions, Isolation, and Migrations
ORMs open and commit transactions for you, and they pick an isolation level - usually the database default. Those defaults disagree. PostgreSQL uses READ COMMITTED, MySQL InnoDB uses REPEATABLE READ, DB2 uses Cursor Stability. The same code can return duplicate rows under READ COMMITTED that it would not under REPEATABLE READ, so behavior shifts when you move databases or when an ORM upgrade quietly changes its defaults. Set the isolation level explicitly for transactions where correctness depends on it, and keep it consistent. Do not inherit it by accident.
Migrations deserve their own boundary. Many ORMs can generate and apply schema changes from your entity definitions, and they track applied migrations in a table they own. That works cleanly when one application owns the database. The moment a second service with a different stack talks to the same schema, ORM-managed migrations start fighting each other. Keep migrations in plain, numbered SQL files, run them as idempotent operations, and treat the ORM as a consumer of the schema rather than its owner.
When to Drop to Raw SQL
The ORM query builder is fine for the common case and bad at the unusual one. Generated SQL can fold logic into constructs that the planner handles poorly - a Common Table Expression that gets materialized and rescanned can run materially slower than the same hashing inlined into the joins. Some operations do not map to one statement at all: Sequelize's findOrCreate issues a SELECT, then on a miss creates and runs a temporary PL/pgSQL function to do the insert with exception handling, and that can still lose to a race condition.
When a query matters and the ORM is generating something baroque, write the SQL yourself. Every mature ORM has an escape hatch for native queries; use it for reporting, bulk operations, and hot paths, and keep the ORM for everything else.
The hard part is that none of this is visible from application code. The ORM swallows the SQL, so an N+1 storm or a fan-out join looks like a slow page, not a query problem. This is where database-side observability pays off: Pulse watches the queries actually reaching the database, surfaces the slow and repeated statements your ORM is generating, and ties them back to the access pattern that produced them - so you catch the N+1 before it reaches production rather than after a customer does.
ORMs are worth using. They earn their place by removing the boilerplate that nobody should write by hand. They just are not a reason to stop thinking about the database. Treat the generated SQL as code you are responsible for, watch what reaches the database, and the abstraction stays an asset instead of becoming the thing that pages you at 2am.


